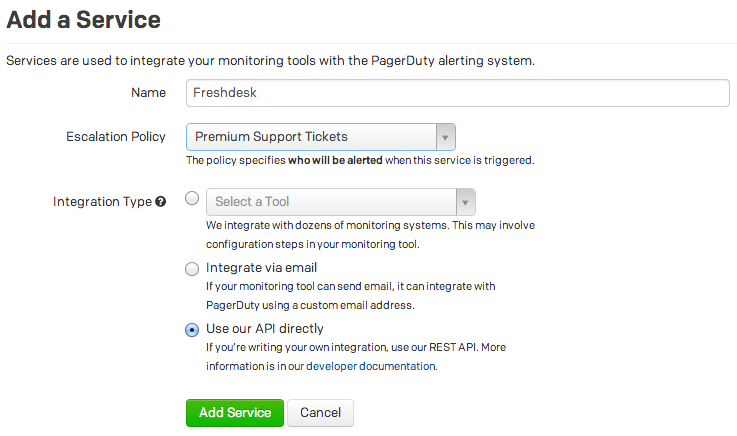
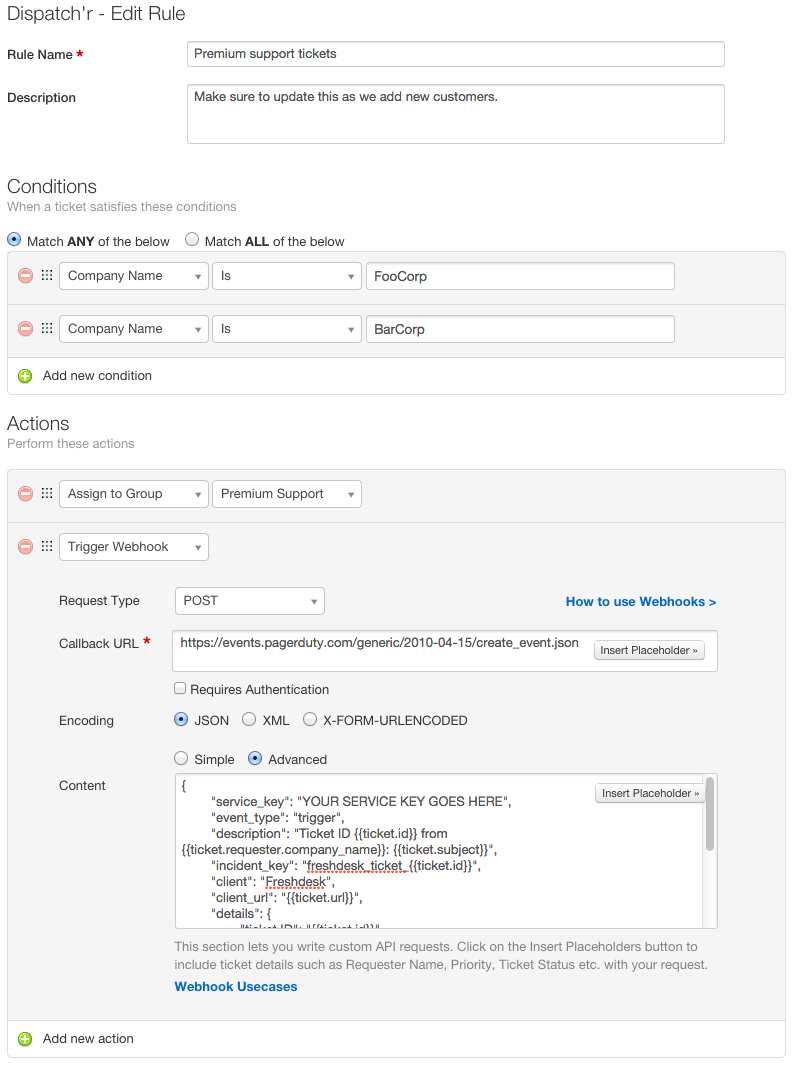
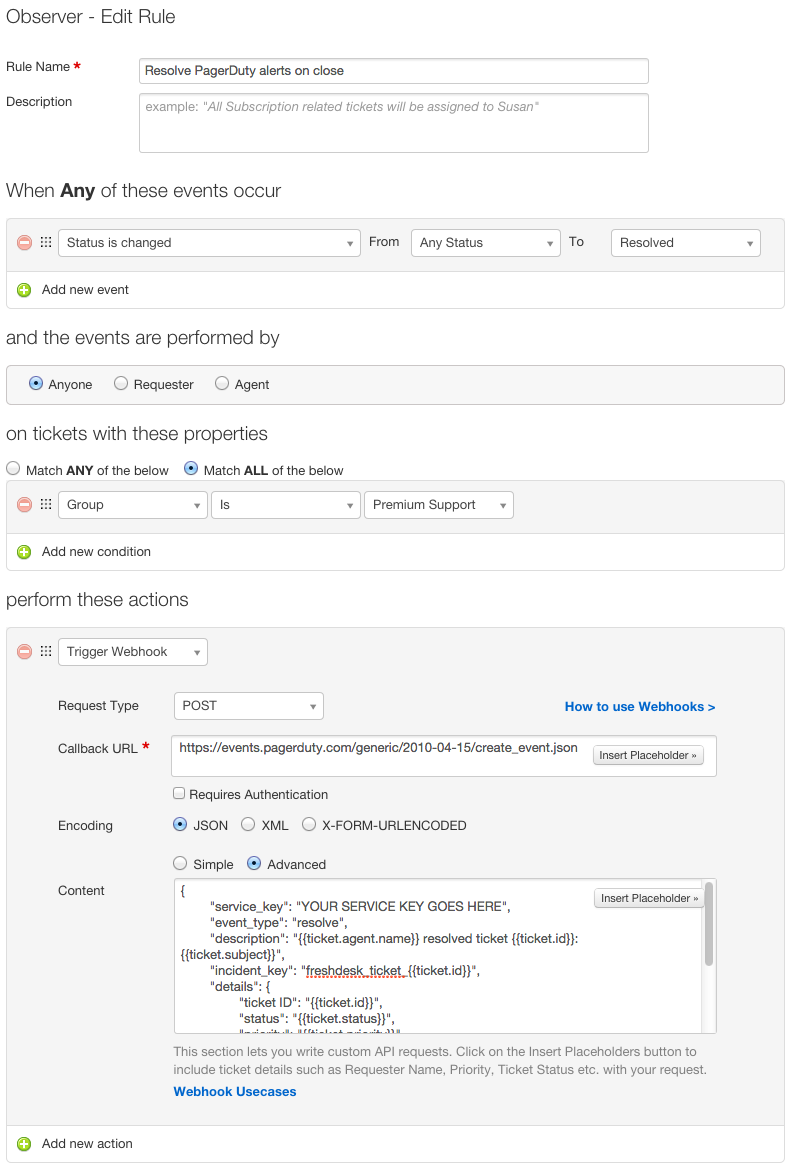
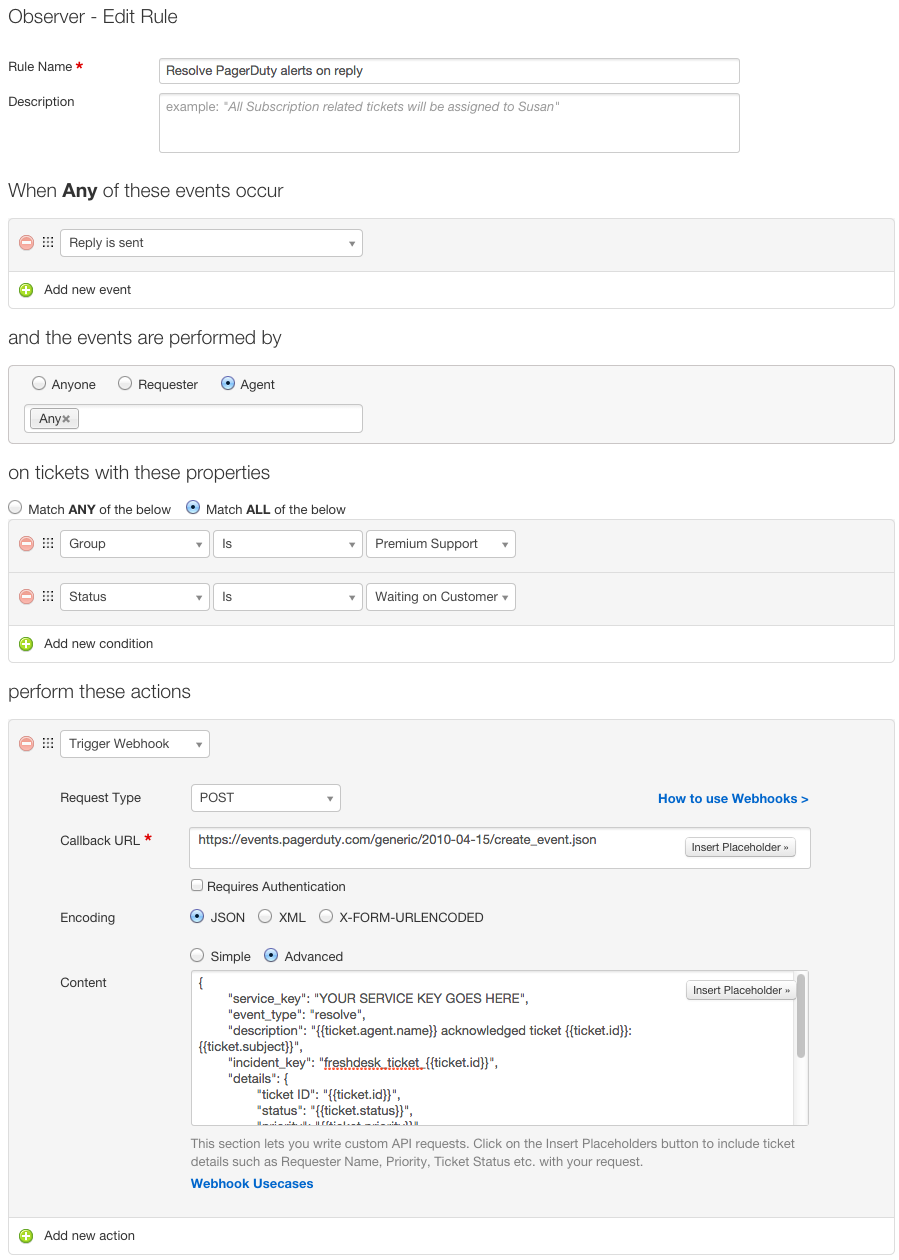
Remembering the Line Ride

I spent the holidays at Disneyland this year with my girlfriend and my family. We stood in numerous lines for hours on end during the busiest week of the year, waiting to see Disney’s take on classic rides such as the Haunted Mansion and Small World.
Their take was fantastic, but this post is not about that.
Standing in line for the Haunted Mansion, listening to people murmur about how agonizing the lines were, it dawned on me that not everybody understood nor appreciated the true origins of these amazing amusement parks. My sister certainly didn’t know, and neither did my girlfriend.
You may not either, so allow me to share a bit of history.
Back to the middle ages
Much of what we’ve come to enjoy in amusement parks originated from fairs in the Middle Ages [1]. The food, the shows. They were further inspired over time by other events and inventions throughout the centuries that followed. One of the innovations in amusement technology that really sparked the modern era of amusement park rides was a classic mechanical ride, the steam-powered carousel, built by Thomas Bradshaw at the Alysham Fair in 1861 [2].
The problem with technological innovations is that they overshadow the simpler pleasures that came before them.
The Line Ride
Long before the carousel, in 1733, people enjoyed a simpler tradition. The humble fairgrounds in those days were unlike the marvels we have today, but were still full of events for children and adults of all ages.
One of the most beloved traditions in those days was known as the Rope Line Ride, or the Line Ride for short. Long lines of rope, attached to tall stakes in the ground, would be laid out in all sorts of patterns, forming paths for the kids to traverse. Common patterns included the spiral, the back-and-forth, and the weave.
Participating in the Line Ride was simple. A person would start at one end, following the line, seeing where it took them (by a garden, perhaps, or a wall of funny drawings), eventually coming out on the other side.
Remember, these were the days when Kick the Can and Hoop Rolling were the rage. The Line Ride was so popular that it was often nearly full of people, but this gave them time to socialize and join together in the admiration of their surroundings.
Evolution of the Line Ride
Times change, as they often do. While once a fun and common attraction, the younger generations began to grow weary of the Line Ride. In 1861, Thomas Bradshaw, the aforementioned inventor of the steam-powered carousel, forever changed the Line Ride by making it a means to an end. He put the carousel at the very end of the Alysham Fair Line Ride.
Now, instead of simply enjoying the Line Ride for what it was, people were passing through it, with great impatience, just to get to the all-new steam-powered carousel.
A new tradition was born. The Line Ride no longer became an attraction itself, but rather simply the Line, a way to control the flow of people leading up to an attraction. This was seen as a very controversial change in its day — after-all, the Line Ride was a tradition going back over a hundred years — and with it came a distrust of the newer attractions by the older generations. Of course, time passed, and the Line became the norm.
The spirit carries on
While often forgotten as an attraction, the Line Ride’s spirit remains today in our terminology and our parks. We’re all familiar with celebrities walking down the rope line, or hearing about people “working the rope line.”
And, of course, the long, grueling lines leading up to the popular attractions at amusement parks and carnivals around the world.
Remembering the Line Ride Read More »